This article edited on MiniTool official page introduces a professional data security term/technology – data replication. Generally, it covers its meaning, types, usage, and application example. Start your reading to learn what it is!
What Is Replication in Computing?
In computing, replication refers to share information to ensure consistency between redundant resources like software or hardware component. Thus, it can improve reliability, accessibility, as well as fault-tolerance.
What Is Data Replication?
Replication in computing can refer to data replication, which means that the same data is stored on multiple storage devices.
About Computation Replication
Besides data replication, replication in computing can also mean computation replication, where the same computational task is executed multiple times.
Both data replication and computation require processes to handle incoming events. Processes for data replication are passive and operate only to maintain the stored data, reply to read requests, and apply updates. While computation replication usually operates to offer fault tolerance and take over an operation if one component fails.
In both of the above situations, the underlying needs are to ensure that the replicas see the same events in equivalent orders. Thus, they stay inconsistent states and any duplicate can reply to queries.

Backup vs Replication
Another process similar to replication is backup. Yet, backup is still different from replication for its saved copy of data keeps unchanged for a long time. Replicas, on the contrary, undergo frequent updates and lose their historical state quickly.
Related article: NAKIVO Issued V9.0 to VM Backup & Replication for Windows Server
Disk Storage Replication
There are several ways of storage replication.
1. Real-time Replication
Usually, real-time/active storage replication is implemented by distributing updates of a block device to several physical hard disks. That way, any file system supported by the operating system (OS) can be replicated without modification as the file system code works on a lever above the block device driver layer. It is implemented either in hardware (in a disk array controller) like RAIDs or in software (in a device driver) like Windows Storage Spaces.
2. Disk Mirroring
The most basic method of storage replication is disk mirroring, which is typical for locally connected disks. The storage industry narrows the definitions. Therefore, mirroring is a local/short-distance operation while replication is extendable across a computer network. So, for replication, the disks can be located in physically distant locations and master-slave database replication mode is usually applied.
![[Wiki] NAND Mirroring Definition/Functions/Possibility/Risks](https://images.minitool.com/minitool.com/images/uploads/2021/07/nand-mirroring-thumbnail.png)
3. Synchronous Replication vs Asynchronous Replication vs Semi-synchronous Replication
The replication’s purpose is to avoid damages from failures or disasters that may occur in one location to improve the ability to recover data. For replication, latency is the key factor for it determines either the type of replication that can be employed or how far apart the sites can be.
The main feature of such cross-site replication is how to write operations that are handled via either synchronous or asynchronous replication. Synchronous replication needs to wait for the destination server’s response in any write operation while asynchronous replication doesn’t.
Synchronous replication guarantees “zero data loss” utilizing atomic write operations where the write operation won’t consider complete until acknowledged by both the local and remote storage.
Most apps wait for a written transaction to finish before proceeding to the next task. Thus, the overall performance greatly decreases. Inherently, performance drops proportionally to distance as a minimum is dictated by the speed of light. For a 10-kilometer distance, the fastest possible roundtrip takes 67 μs whereas an entire cached write completes in around 10 – 20 μs.
Many commercial synchronous replication systems don’t freeze when the remote replica fails or loses connection (behavior which guarantees zero data loss) but proceed to operate locally, losing the desired zero recovery point objective (RPO).
In asynchronous replication, the write operation is considered finish as soon as local storage acknowledges it. Remote storage is updated with a small lag. So, performance is largely increased. Yet, in case of a local storage failure, the remote storage isn’t guaranteed to have the current copy of data. So, the most recent data may be lost.
Typically, a semi-synchronous replication considers a write operation complete when acknowledged by local storage and received or logged by the remote server. While actually, the remote write is performed asynchronously. Thus, semi-synchronous replication offers better performance but remote storage will lag behind the local storage. Also, there is no guarantee of durability, seamless transparency, in the case of local storage failure.
4. Point-in-time Replication
Point-in-time replication produces periodic snapshots that are replicated instead of primary storage. This is intended to replicate only the changed data instead of the entire volume. As less info is replicated by this method, duplication can occur over less-expensive bandwidth links such as iSCSI or T1 fiberoptic lines.

File-based Replication
File-based replication conducts data replication at the logical level, individual data files for example, instead of the storage block level. There are many methods to carry out file-level replication with most of them rely on software.
1. Capture with a Kernel Driver
A kernel driver especially a filter driver can be used to intercept calls to the filesystem functions, capturing any activity as it happens. Real-time active virus checkers employ the same tech. At this level, logical file operations are captured when open, edit, delete, etc. the file.
The kernel driver transmits those commands to another process, generally over a network to a different machine, which will mimic the operations of the source machine. Be similar to block-level storage replication, the file-level replication permits both synchronous and asynchronous modes.
In synchronous mode, write operations on the source machine are held and not allowed to occur until the destination machine has acknowledged the successful replication. This mode is rare with file replication software.
File replication services allow for informed decisions about replication based on the location and type of the file. For instance, temporary files or parts of a filesystem that hold no business value could be excluded.
The data transmitted can also be more granular. If a program writes 200 bytes, only the 200 bytes are transferred instead of a whole disk block that is almost 4,096 bytes. Substantially, this reduces the amount of data sent from the source machine and the storage burden on the target device.
However, this software-only solution has shortcomings including the requirement for implementation and maintenance on the OS level and an increased burden on the machine’s processing power.
![[Wiki] Microsoft System Center Endpoint Protection Review](https://images.minitool.com/minitool.com/images/uploads/2021/05/system-center-endpoint-protection-thumbnail.png)
2. File System Journal Replication
Like database transaction logs, many file systems are capable of journaling their activities. The journal can be sent to another machine either periodically or in real-time by streaming. On the replica side, the journal can be used to playback file system modifications. For example, Microsoft’s System Center Data Protection Manager (DPM) conducts periodic updates through file system journal replication.
also read: What Is Journaling File System and Its Advantages/Disadvantages?
3. Batch Replication
Batch replication is the process of comparing the source and destination file systems and ensuring that the destination matches the source. The major benefit is that such data replication solutions are free or inexpensive. The drawback is that the process of syncing them uses many system resources. As a result, such a process rarely runs. One of the notable implementations of batch replication is rsync.
Conduct File-based Replication with MiniTool ShadowMaker
MiniTool ShadowMaker is a professional and reliable data replication tool. If enables you to sync files/folders from one location to another with the destination can be internal or external addresses, or remote network location (NAS). Also, this file replication service lets you set up a schedule to automatically synchronize files, compare source and destination contents before syncing, as well as filter certain files from replication.
Now, let’s see how to use MiniTool ShadowMaker to replicate data.
MiniTool ShadowMaker TrialClick to Download100%Clean & Safe
1. Download, install, and launch MiniTool ShadowMaker on your source machine.
2. If it asks for purchase, just click the Keep Trial button in the upper-right to enjoy its features for free.
3. When it enters its main interface, navigate to the Sync tab from the top menu.
4. In the Sync tab, click on the Source module to select the files or folders you’d like to replicate.
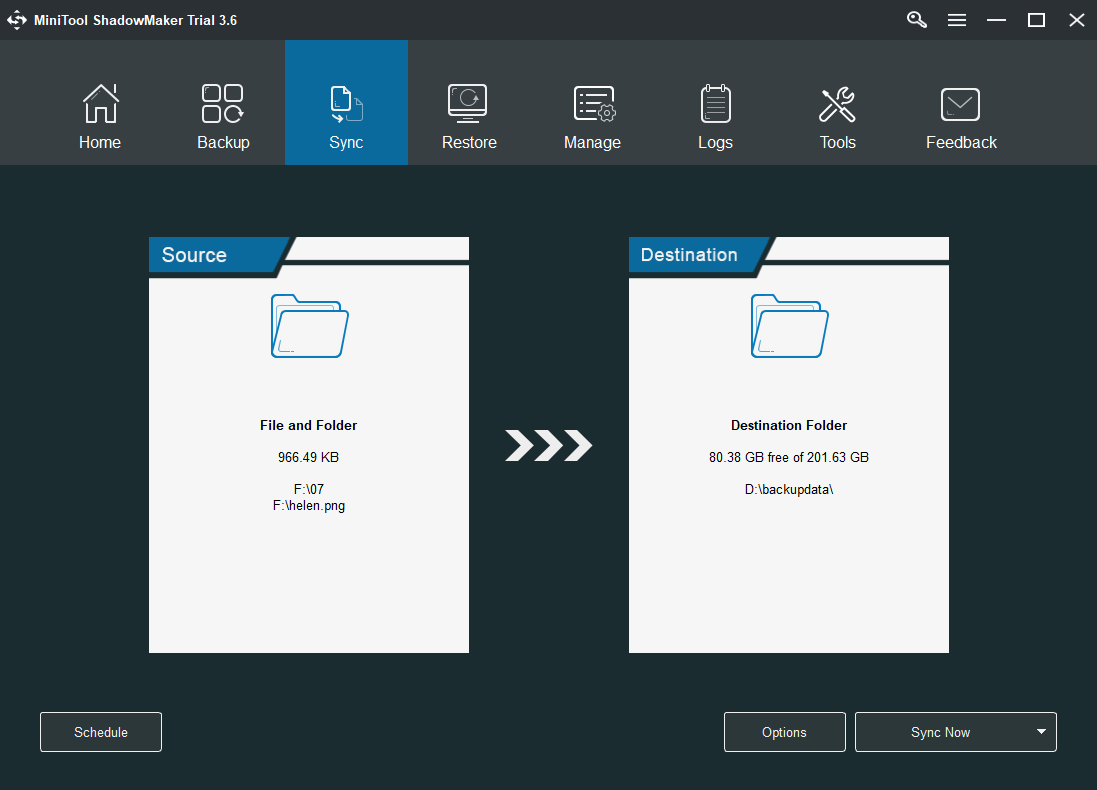
5. Click on the Destination module to choose where you plan to save the replica. You can select any local location or a remote shared location.
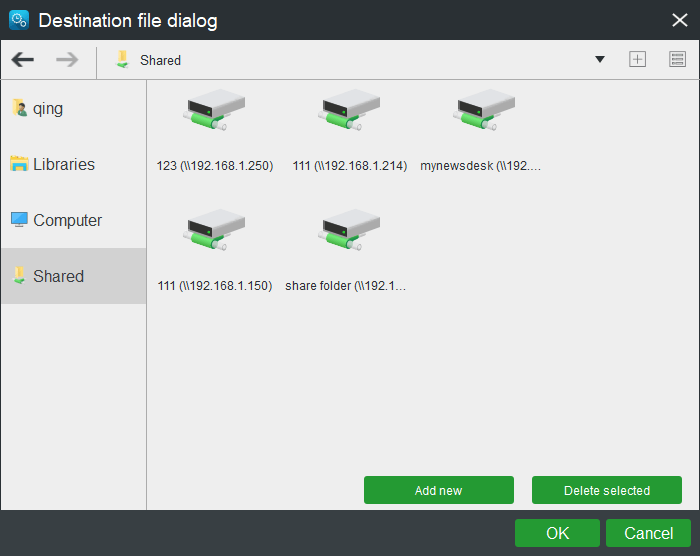
6. Click on the Schedule button in the bottom-left of the Sync tab, switch on the schedule settings in the popup, and choose a proper data replication schedule, daily, weekly, monthly, or on event.
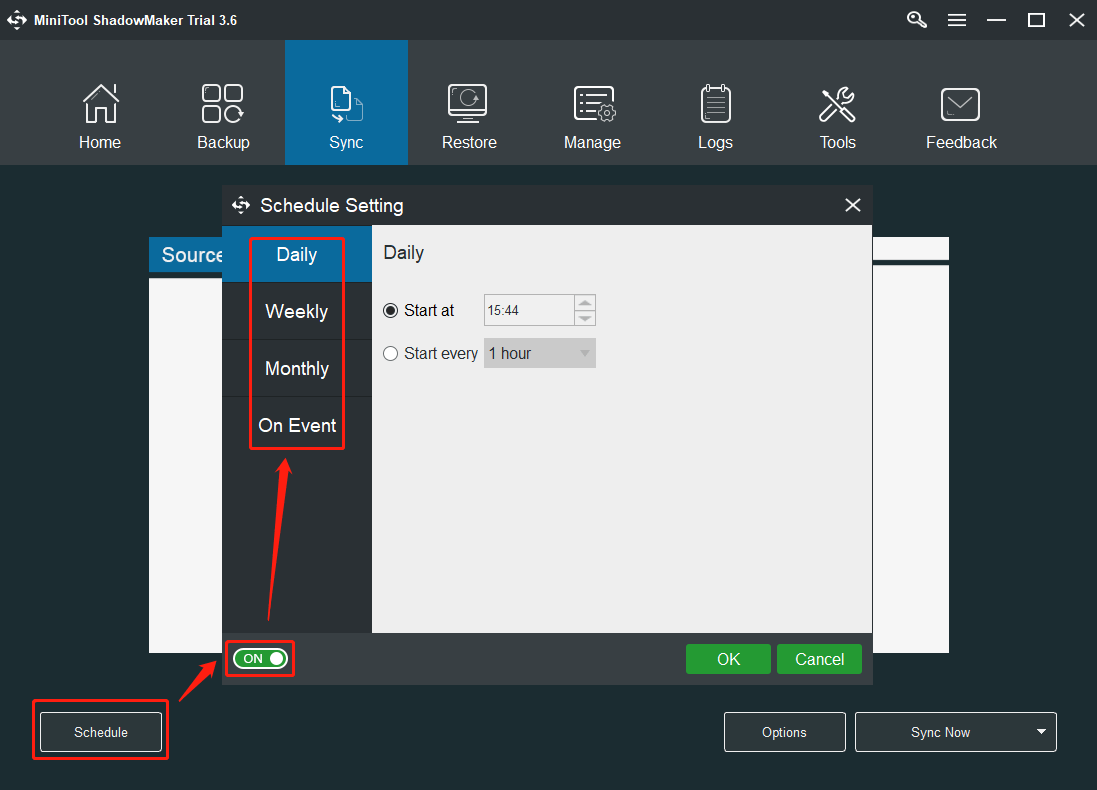
7. Click on the Options button in the lower-right. In the Options window, you can compare the data by file time, file size, or file content, which will increase the replication time. Also, you are able to filter certain unnecessary files like hibernation files, page files, recycle bin files, swap files, system volume information, and so on.
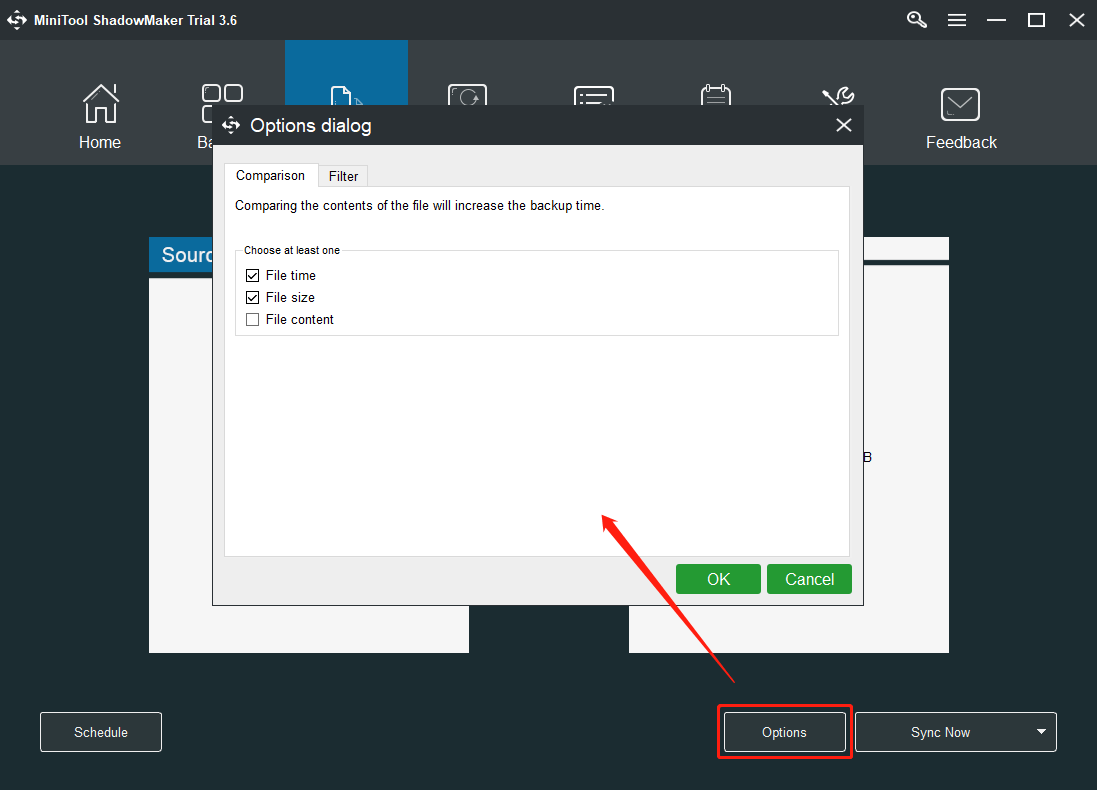
8. Finally, click Sync Now to start the file replication process.
Besides data replication, MiniTool ShadowMaker can also back up files/folders, OS, partitions/volumes, as well as the entire hard disk in case of data loss.
Primary-backup and Multi-primary Replication
Many traditional approaches to data replication rely on a primary backup model that one device or process has unilateral control over the other devices or processes. For example, the primary might perform some computation, streaming a log of updates to a standby backup process that can then take over if the primary fails.
That approach is common for database replication. Yet, it has the risk that if a portion of the log is lost during a failure, the backup might not be in a state identical to the primary and transactions could then be lost.
A disadvantage of primary backup schemes is that only one is performing operations. fault-tolerance is gained, but the identical backup system doubles the costs. Thus, alternative schemes come into being. Such schemes have a group of replicas that could cooperate with each process acting as a backup while also handling a share of the workload.
Those replacement schemes are called multi-primary replication schemes. However, the multi-primary schemes are considered to degrade performance by computer scientist Jim Gray. He worked out a solution that is to partition the data, which is only available in cases where data has a natural partitioning key.

Later, the virtual synchrony mode was proposed and emerged as a widely employed standard. It allows a multi-primary approach in which a group of processes cooperates to parallelize some aspects of request processing. However, this scheme can only be applied for some forms of in-memory data but can provide linear speedups in the size of the group. C-Ensemble, Ensemble, Horus, Phoenix, Quicksilver, Isis Toolkit, Spread, Totem, Transis, and WANdisco adopt the virtual synchrony technique.
Finally
After reading the above content, you must have a better understanding of data replication. If you get some genius idea about this topic, feel free to share it with others in the below comment section. Or, if encounter any problem while using MiniTool ShadowMaker, just contact its support team at [email protected].
About The Author

Position: Columnist
Helen Graduated from university in 2014 and started working as a tech editor in the same year. Her articles focus on video creation, editing, and conversion. She also has a good knowledge of disk management and data backup & recovery. Through an in-depth exploration of computer technology, Helen has successfully helped thousands of users solve their annoying problems.